2015年,迷你电脑主机大走低价路线。以往动辄上百美金的开发板,在过去一年集体大幅度跳水,售价低至10美元左右,创客圈直呼业界良心。那么2015年究竟有哪些“白菜价”的开发板上市了呢?硬创邦这里为大家做详细盘点。作为开源硬件的代表作品,Raspberry开启了迷你Linux电脑的先河。
[信息图]搜狗大数据:00后最爱的手机品牌是小米_Sogou 搜狗_cnBeta.COM
搜狗输入法是目前国内Android手机用户使用最多的输入法,占比超过1/3,作为每天必用的工具,它也收集了价值连城的大数据。今天,搜狗手机输入法就盘点了2015《我和2015输入法的那点事》,数据显示,80后最喜欢的手机品牌是iPhone,而00后最喜欢的手机品牌是小米。
自主架构处理器有没有用?_硬件_cnBeta.COM
对于手机处理器来说,大家不用过多关注核数与主频,应该把目光多投向架构与工艺。判断工艺优劣还是非常容易的,基本就是纳米数越小代表越先进,采用
FinFET晶体管比传统2D晶体管更好。但要判断架构优劣就比较难了,因为有公版和自主架构之分,公版架构了解清楚了命名规则大概就能知晓一二,自主架
构由于厂商不同,想从命名上判断就非常困难。
这些障碍最终阻碍了我们对于一颗SoC优劣的认识,到底是自主架构强还是公版架构好?不同自主架构间性能孰强孰弱?
对于这些疑问,我们先从指令集聊起。 继续阅读“自主架构处理器有没有用?_硬件_cnBeta.COM”
买个不到称心的智能镜?那就自己动手打造一套吧!_硬件_cnBeta.COM
近年来我们不时能听到“智能镜子”的新闻(或者在电影中看到),但若你真想买一个的话,就会发现事情并没有那么简单。鉴于市售产品无能满足自己的需求,动手能力强的人就决定自己亲手做一个了,至少外媒Medium的Max Braun就是这么干的。DIY所需要的,包括了一面双向镜、一块显示面板、控制板、一堆附加组件、以及手工活。
最新android sdk安装方法以及哪些是必须安装的说明,亲测下载速度很快
除了镜像之外全下就是了,挂一晚上机就可下完
使用国内Google服务器下载SDK的方法:
- ping http://g.cn;得到国内的google服务器地址
- Android SDK Manager->Tools->Options
- 按下图设置:
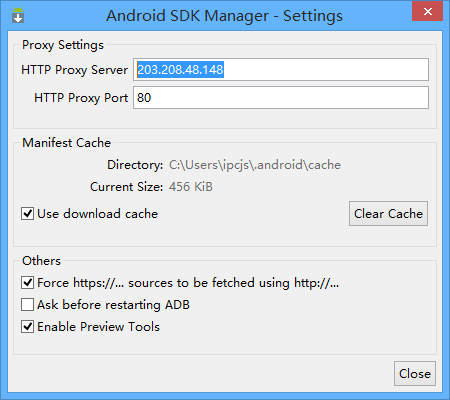 继续阅读“最新android sdk安装方法以及哪些是必须安装的说明,亲测下载速度很快”
继续阅读“最新android sdk安装方法以及哪些是必须安装的说明,亲测下载速度很快”
改变人类历史的17大数学方程_Top10 十大_cnBeta.COM
在笔者看来,宇宙中的通用语言有两种,一种是数学,另一种是艺术。数学以最简洁的方式,把复杂的宇宙现象和规律淋漓尽致的展现出来,正所谓宇宙不言,大美如斯!2013年,数学家和科普作家Ian Stewart 发表了他的著作——《改变世界的17个方程》,向大家诠释了人类历史上最伟大的17个方程。
Linux下Tomcat的安装配置 – 小菜鸟的天地 – 博客频道 – CSDN.NET
先按照tomcat版本要求配置jdk版本,然后部署tomcat,按这篇教程我遇到错误,看不到测试页面,改端口8081,catalina.sh stop 然后 catalina.sh start重启之后可以看到测试页面了。其它错误最后面有解决方案。 继续阅读“Linux下Tomcat的安装配置 – 小菜鸟的天地 – 博客频道 – CSDN.NET”
hadoop2提交到Yarn: Mapreduce执行过程reduce分析3-Hadoop2|YARN-about云开发
问题导读:
1.Reduce类主要有哪三个步骤?
2.Reduce的Copy都包含什么过程?
3.Sort主要做了哪些工作?
继续阅读“hadoop2提交到Yarn: Mapreduce执行过程reduce分析3-Hadoop2|YARN-about云开发”
hadoop2提交到Yarn: Mapreduce执行过程分析2-Hadoop2|YARN-about云开发
问题导读:
1.hadoop哪些数据类型,是如何与Java数据类型对应的?
2.ApplicationMaster什么时候启动?
3.YarnChild进程什么时候产生?
4.如果在recuece的情况下,map任务完成暂总任务的多少百分比?
5.run的执行步骤是什么?
6.哪个方法来执行具体的map任务?
7.获取配置信息为哪个类?
8.TaskAttemptContextImpl还增加了什么信息?
继续阅读“hadoop2提交到Yarn: Mapreduce执行过程分析2-Hadoop2|YARN-about云开发”
hadoop2提交到Yarn: Mapreduce执行过程分析1-Hadoop2|YARN-about云开发
1.为什么会产生Yarn?
2.Configuration类的作用是什么?
3.GenericOptionsParser类的作用是什么?
4.如何将命令行中的参数配置到变量conf中?
5.哪个方法会获得传入的参数?
6.如何在命令行指定reduce的个数?
7.默认情况map、reduce为几?
8.setJarByClass的作用是什么?
9.如果想在控制台打印job(maoreduce)当前的进度,需要设置哪个参数?
10.配置了哪个参数,在提交job的时候,会创建一个YARNRunner对象来进行任务的提交?
11.哪个类实现了读取yarn-site.xml、core-site.xml等配置文件中的配置属性的?
12.JobSubmitter类中的哪个方法实现了把job提交到集群?
13.DistributedCache在mapreduce中发挥了什么作用?
14.对每个输入文件进行split划分,是物理划分还是逻辑划分,他们有什么区别?
15.分片的大小有哪些因素来决定
16.分片是如何计算得来的?
继续阅读“hadoop2提交到Yarn: Mapreduce执行过程分析1-Hadoop2|YARN-about云开发”
hadoop 2.2 集群 和eclipse 怎么配置_百度知道
Eclipse调用hadoop运行MR程序其实就是普通的java程序可以提交MR任务到集群执行而已。在Hadoop1中,只需指定jt(jobtracker)和fs(namenode)即可,一般如下:
Configuration conf = new Configuration();
conf.set(“mapred.job.tracker”, “192.168.128.138:9001”);
conf.set(“fs.default.name”,”192.168.128.138:9000″);
上面的代码在hadoop1中运行是ok的,完全可以使用java提交任务到集群运行。但是,hadoop2却是没有了jt,新增了yarn。这个要如何使用呢?最简单的想法,同样指定其配置,试试。 继续阅读“hadoop 2.2 集群 和eclipse 怎么配置_百度知道”
Hadoop基础教程之搭建开发环境及编写Hello World – 程序园
整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA。在linux下开发JAVA还数eclipse方便。 继续阅读“Hadoop基础教程之搭建开发环境及编写Hello World – 程序园”
Hadoop基础教程之HelloWord – 程序园
我们把hadoop下载、安装、运行起来,最后还执行了一个Hello world程序,看到了结果。现在我们就来解读一下这个Hello Word。
OK,我们先来看一下当时在命令行里输入的内容: 继续阅读“Hadoop基础教程之HelloWord – 程序园”
Hadoop基础教程之高级编程 – 程序园
从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤:
1.输入(input):将输入数据分成一个个split,并将split进一步拆成<key, value>。
2.映射(map):根据输入的<key, value>进生处理,
3.合并(combiner):合并中间相两同的key值。
4.分区(Partition):将<key, value>分成N分,分别送到下一环节。
5.化简(Reduce):将中间结果合并,得到最终结果
6.输出(output):负责输入最终结果。
其中第3、4步又成洗牌(shuffle)过程。 继续阅读“Hadoop基础教程之高级编程 – 程序园”
通过eclipse调试MapReduce任务 — 其他 — IT技术博客大学习 — 共学习 共进步!
利用MapReduce利器作开发,不论从思想上还是技能上都是新的体验。以下罗列下如何利用eclipse调试MR任务。
(本人环境:hadoop 1.0.2,部署在linux上,本地windows开发)
1、安装hadoop。
先在linux上安装好hadoop,为更接近线上环进,我的是安装成Cluster
注意要远程访问相关端口,conf/mapred-site.xml中localhost:9001中需要换成ip加端口。
sh bin/start-all.sh启动,先按文档命令行跑一下example的wordcount。
我安装好运行example遇到了XML解析的错(原因应该是${java.home}/lib/jaxp.properties没有设置,见:javax.xml.xpath.XPathFactory.newInstance(uri)的注释),后来手动加了xalan-j_2.7.0.jar、xercesImpl-2.7.1.jar、xml-apis-2.7.1.jar、xmlenc-0.52.jar、serializer-2.7.1.jar几个包解决。
2、下载hadoop eclipse plugin (最新只有0.20.3,不过也能使用),将jar放到eclipse/plugins下,启动eclipse
这个插件比较简陋,只有一个设置项:Window->Preferences->Hadoop Map/Reduce,设置Hadoop的安装路径,解压一份跟运行hadoop同版本的到本机并指向就行了(我的使用smb映射)
建ecplise工程,把WordCount的示例代码复制一份吧,有些hadoop相关的jar需要引用。
Run As->Run On Hadoop设置Map/Reduce Master的IP,端口为9000, DFS Master端口为9001
这样,不出意外的话就能在eclipse里运行Map/Reduce程序了。 继续阅读“通过eclipse调试MapReduce任务 — 其他 — IT技术博客大学习 — 共学习 共进步!”
如何在eclipse上调试hadoop的笔记_百度知道
步骤
修改mapred-site.xml文件,添加如下配置: 继续阅读“如何在eclipse上调试hadoop的笔记_百度知道”
hadoop2.2.0 源码远程调试_王维_新浪博客
note: 只在linux上面调试,windows下面会有脚本执行的问题,可能需要安装cygwin可以解决. 继续阅读“hadoop2.2.0 源码远程调试_王维_新浪博客”
eclipse debug调试mapreduce程序 – 蓝狐乐队的个人空间 – 开源中国社区
1、将mapred-site.xml文件拷贝一份到项目中 继续阅读“eclipse debug调试mapreduce程序 – 蓝狐乐队的个人空间 – 开源中国社区”
hadoop研究:mapreduce研究前的准备工作 – 夏天的森林 – 博客园
继续研究hadoop,有童鞋问我,为啥不接着写hive的文章了,原因主要是时间不够,我对hive的研究基本结束,现在主要是hdfs和mapreduce,能写文章的时间也不多,只有周末才有时间写文章,所以最近的文章都是写hdfs和mapreduce。不过hive是建立在hdfs和mapreduce之上,研究好hdfs和mapreduce也是真正用好hive的前提。
今天的内容是mapreduce,经过这么长时间的学习,我对hadoop的相关技术理解更加深入了,这回我会尽全力讲解好mapreduce。 继续阅读“hadoop研究:mapreduce研究前的准备工作 – 夏天的森林 – 博客园”
eclipse中mapreduce程序编译打包出错的解决
必须在项目中手动添加MANIFEST.MF ,并写入如下内容
例如我们打包的jar为 Test.jar
Manifest-Version: 1.0
Main-Class: windows.VideoWindow
Class-Path: lib\org.eclipse.swt_3.3.0.v3346.jar lib\org.eclipse.swt.win32.win32.x86_3.3.0.v3346.jar
否则报错:
could not find main class. 继续阅读“eclipse中mapreduce程序编译打包出错的解决”