启动hadoop,但ssh 端口不是默认的22怎么样?好在它可以配置。在conf/hadoop-env.sh里改下。如:
export HADOOP_SSH_OPTS=”-p 1234″
代码剪辑,记录代码人生的点点滴滴!
启动hadoop,但ssh 端口不是默认的22怎么样?好在它可以配置。在conf/hadoop-env.sh里改下。如:
export HADOOP_SSH_OPTS=”-p 1234″
Linux防火墙Iptable如何设置只允许某个ip访问80端口,只允许特定ip访问某端口?参考下面命令,只允许46.166.150.22访问本机的80端口。如果要设置其他ip或端口,改改即可。 继续阅读“Linux防火墙Iptable如何设置只允许某个ip访问80端口,只允许特定ip访问某端口 – Linux VPS租用 – 国外/美国服务器租用”
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。 继续阅读“Hadoop集群(第8期)_HDFS初探之旅 – 虾皮 – 博客园”
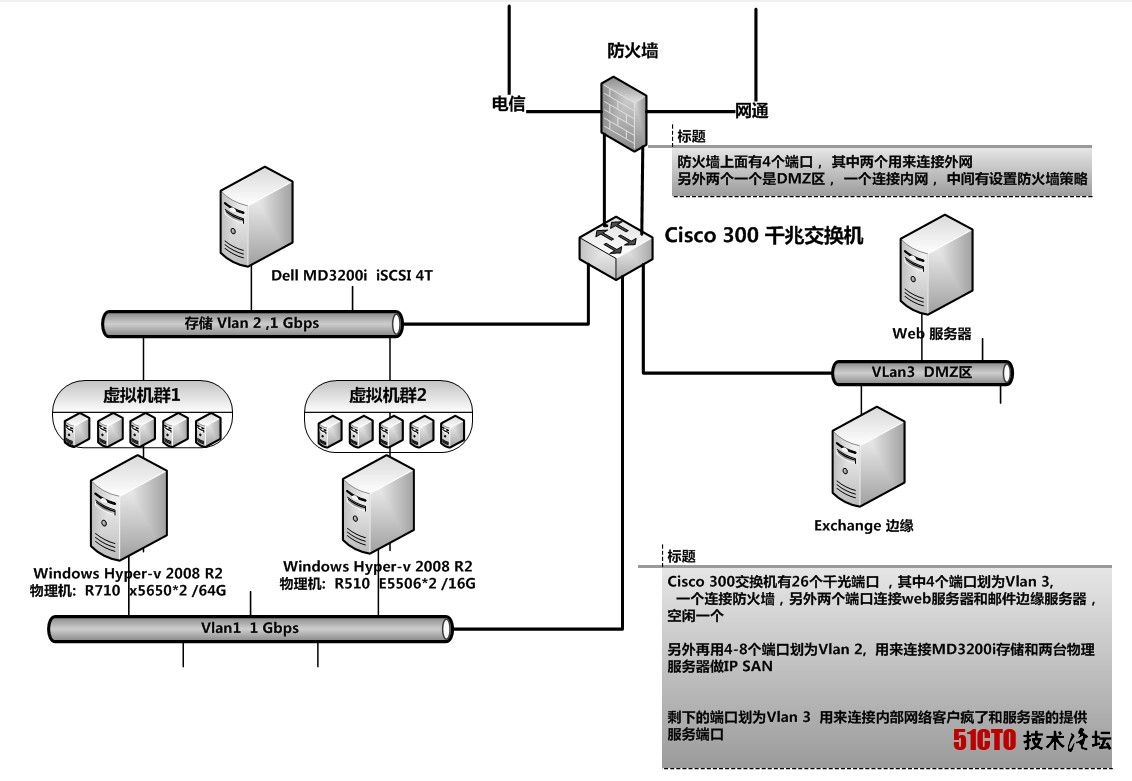
刚配置完hadoop1.0.4发现对配置文件还是不太了解,就baidu了下,跟大家分享下 。常用的端口配置 继续阅读“hdfs 常用端口和 hdfs-default配置文件参数的意义(转载) – Hadoop分布式数据分析平台-炼数成金-Dataguru专业数据分析社区”
-福利贴-
资源1: 受Maven折磨的同学来福利了,Eclipse非maven版本下载地址
JEECG 开发平台(V3系列)
JEEWX微信管家系统(V2系列) 继续阅读“JEECG 开源社区所有开源项目下载(总览) – Jeecg& 官方资讯 – JEECG微云快速开发平台-官方论坛 – ��ҳ”
分布式文件系统主要用于解决海量数据存储的问题,如Goolge、Facebook等大型互联网企业都使用分布式文件系统作为数据存储的基础设施,并在其上构建很多服务,分布式文件系统通常采用三副本的策略来保证数据的可靠性,但随着应用数据量的不断膨胀,三副本策略为可靠性牺牲的存储空间也越来越大,如何在不降低数据可靠性的基础上,进一步降低存储空间成本? Facebook将erasure code应用到内部HDFS集群中,该方案使用erasure code代替传统的三副本策略,在保持集群可用性不变的情况下,节省了数PB的存储空间,Facebook的实现方案(HDFS RAID)目前已贡献给开源社区。 继续阅读“HDFS RAID实现方案-zyd_cu-ChinaUnix博客”
这里简单讲下hadoop的网络拓扑距离的计算 继续阅读“HDFS 数据流-fjsm20Linux-ChinaUnix博客”
分布式文件系统比较出名的有HDFS 和 GFS,其中HDFS比较简单一点。本文是一篇描述非常简洁易懂的漫画形式讲解HDFS的原理。比一般PPT要通俗易懂很多。不难得的学习资料。
1、三个部分: 客户端、nameserver(可理解为主控和文件索引类似linux的inode)、datanode(存放实际数据的存server)
HDFS(Hadoop
Distributed Filesystem)客户端通过被称之为Namenode单服务器节点执行文件系统原数据操作,同时DataNode会与其他DataNode进行通信并复制数据块以实现冗余,这样单一的DataNode损坏不会导致集群的数据丢失。 继续阅读“HDFS Namenode是如何工作的? – tenfyguo的技术专栏 – 博客频道 – CSDN.NET”
前阵子,公司的hadoop从hadoop1.02升级到hadoop2.4.1,记录下升级的步骤和遇到的问题,和大家分享,希望别人可以少走一些弯路 继续阅读“hadoop2升级的那点事情(详解) – ggjucheng – 博客园”
By default,when output hive table to file ,columns of the Hive table are separated by ^A character (that is \001). 继续阅读“[HIVE-3682] when output hive table to file,users should could have a separator of their own choice – ASF JIRA”
Hive三种不同的数据导出的方式,根据导出的地方不一样,将这些方法分为三类: 继续阅读“Hive三种不同的数据导出的方式-helianthus_lu-ChinaUnix博客”
在hive中运行的sql有很多是比较小的sql,数据量小,计算量小.这些比较小的sql如果也采用分布式的方式来执行,那么是得不偿失的.因为sql真正执行的时间可能只有10秒,但是分布式任务的生成得其他过程的执行可能要1分钟.这样的小任务更适合采用lcoal mr的方式来执行.就是在本地来执行,通过把输入数据拉回客户端来执行. 继续阅读“hive中的local mr – 东杰书屋 – 博客频道 – CSDN.NET”
原数据有两列。第一列是打电话总时长,第二列是打电话占打接电话比。两列数据都已经标准化过了。一开始是逗号分割,每行两个数字。
拿到数据后,先使用R来看一下,毕竟只有两个维度,plot一下就好了。 继续阅读“mahout0.9 聚类小实验 – 插肩美女不屑看,三千码友在身旁 – 开源中国社区”
聚类算法及聚类评估 Silhouette 简介
聚类算法简介
聚类(clustering)是属于无监督学习(Unsupervised learning)的一种,用来把一组数据划分为几类,每类中的数据尽可能的相似,而不同类之间尽可能的差异最大化。通过聚类,可以为样本选取提供参考,或进行根源分析,或作为其它算法的预处理步骤。 继续阅读“为 Mahout 增加聚类评估功能”
Answer:
程序里面需要打开多个文件,进行分析,系统一般默认数量是1024,(用ulimit -a可以看到)对于正常使用是够了,但是对于程序来讲,就太少了。 继续阅读“hadoop常见错误及解决办法! – 心如大海 – ITeye技术网站”