在深入云存储系统Swift核心组件:Ring实现原理剖析和深入云存储系统Swift核心组件:Ring数据结构及构建、重平衡操作两篇博文中,我们详细地分析了Swift中数据的映射机制和具体操作。那么在集群中的每一台存储节点上,Swift是如何实现Account、Container、Object的具体存储呢?本篇旨在分析Storage
node与partition,partition与data间的映射关系在实际存储目录中的以何种格式存储,即怎么存,存什么。
在Storage node上运行着Linux系统并使用了XFS文件系统,逻辑上使用一致性哈希算法将固定总数的partition映射到每个Storage
node上,每个Data也使用同样的哈希算法映射到Partition上,其层次结构如下图所示:
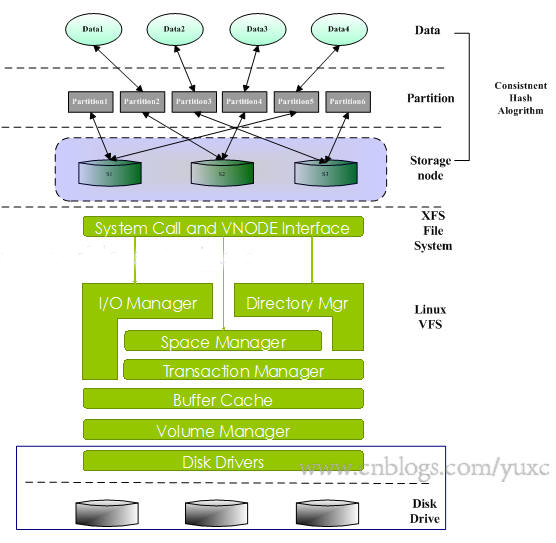
以我们的一台storage node sws51为例,该device的文件路径挂载到/srv/node/sdc,目录结构如下所示:
root@sws51:/srv/node/sdc# ls
accounts async_pending containers objects quarantined
tmp
其中accounts、containers、objects分别是账号、容器、对象的存储目录,async_pending是异步待更新目录,quarantined是隔离目录,tmp是临时目录。
1.objects目录
在objects目录下存放的是各个partition目录,其中每个partition目录是由若干个suffix_path名的目录和一个hashes.pkl文件组成,suffix_path目录下是由object的hash_path名构成的目录,在hash_path目录下存放了关于object的数据和元数据,object存储目录的层次结构如图2所示。
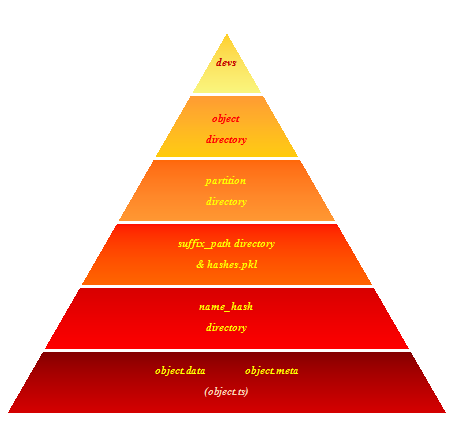
hashes.pkl是存放在每个partition中的一个2进制pickle化文件。例如:
root@sws50:/srv/node/sdc/objects/100000#
ls 8bd hashes.pkl
In [1]: with open(‘hashes.pkl’,
‘rb’) as fp:
…: import pickle
…: hashes = pickle.load(fp)
In [2]: hashes
Out[2]: {‘8bd’: ‘9e99c8eedaa3197a63f685dd92a5b4b8’}
‘8bd’是suffix_dir,而9e99c8eedaa3197a63f685dd92a5b4b8则是该partition下数据的md5哈希值。
Object path生成过程
object的存储路径由object server进程内部称为DiskFile类初始化时产生,过程如下
1.由文件所属的account、container和object名称产生’/account/container/object’格式的字符串,和HASH_PATH_SUFFIX组成新的字符串,调用hash_path函数,生成md5
hash值name_hash。其中HASH_PATH_SUFFIX作为salt来增加安全性,HASH_PATH_SUFFIX值存放在/etc/swift/swift.conf中。
2. 调用storage_directory函数,传入DATADIR,
partition, hash_path参数生成DATADIR/partition/name_path[-3:]/name_path格式字符串
3. 连结path/devcie/storage_directory(DATADIR,
partition,name_ hash)生成数据存储路径datadir
4. 调用normalize_timestamp函数生成“16位.5位”的时间戳+扩展名的格式生成对象名称
例如,某object的存储路径为:/srv/node/sdc/objects/19892/ab1/136d0ab88371e25e16663fbd2ef42ab1/1320050752.09979.data
其中每个目录分别表示:

Object数据
Object的数据存放在后缀为.data的文件中,它的metadata存放在以后缀为.meta的文件中,将被删除的Object以一个0字节后缀为.ts的文件存放。
2.accounts目录
在accounts目录下存放的是各个partition,而每个partition目录是由若干个suffix_path目录组成,suffix_path目录下是由account的hsh名构成的目录,在hsh目录下存放了关于account的sqlite
db,account存储目录的层次结构如图4所示。
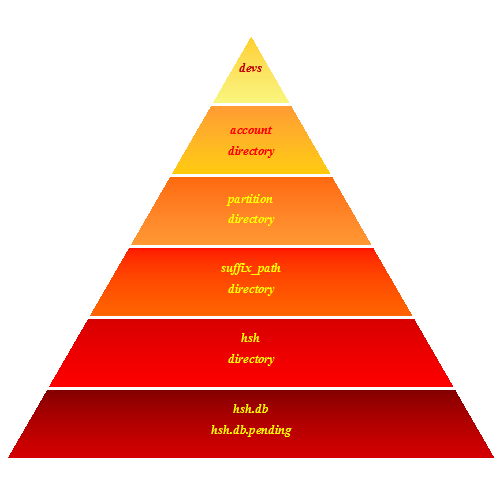
Account path生成过程
account使用AccountController类来生成path,其过程与object类似,唯一的不同之处在于,account的db命名调用hash_path(account)来生成,而不是使用时间戳的形式。例如,某account的db存储路径为:/srv/node/sdc/accounts/20443/ac8/c7a5e0f94b23b79345b6036209f9cac8/
c7a5e0f94b23b79345b6036209f9cac8.db

Account db数据
在account的db文件中,包含了account_stat、container、incoming_sync
、outgoing_sync 4张表。
表account_stat是记录关于account的信息,如名称、创建时间、container数统计等等,其schema如下
CREATE TABLE account_stat (
account TEXT,
created_at TEXT,
put_timestamp TEXT DEFAULT '0',
delete_timestamp TEXT DEFAULT '0',
container_count INTEGER,
object_count INTEGER DEFAULT 0,
bytes_used INTEGER DEFAULT 0,
hash TEXT default '00000000000000000000000000000000',
id TEXT,
status TEXT DEFAULT '',
status_changed_at TEXT DEFAULT '0',
metadata TEXT DEFAULT ''
);
account表示account名称,created_at表示创建时间,put_timestamp表示put
request的时间戳,delete_timestamp表示delete request的时间戳,container_count为countainer的计数,object_count为object的计数,bytes_used表示已使用的字节数,hash表示db文件的hash值,id表示统一标识符,status表示account是否被标记为删除,status_changed_at表示状态修改时间,metadata表示account的元数据。
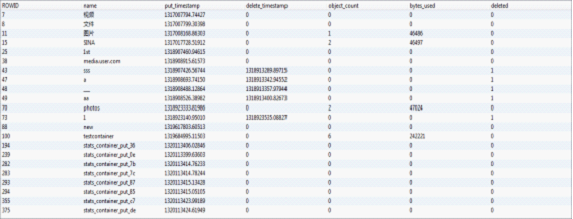
以test账号为例,该db的表account_stat中存放了以下数据项:

表container记录关于container的信息,其schema如下
CREATE TABLE container (
ROWID INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
put_timestamp TEXT,
delete_timestamp TEXT,
object_count INTEGER,
bytes_used INTEGER,
deleted INTEGER DEFAULT 0
);
CREATE INDEX ix_container_deleted_name ON
container (deleted, name);
CREATE TRIGGER container_delete AFTER DELETE ON container
BEGIN
UPDATE account_stat
SET container_count = container_count - (1 - old.deleted),
object_count = object_count - old.object_count,
bytes_used = bytes_used - old.bytes_used,
hash = chexor(hash, old.name,
old.put_timestamp || '-' ||
old.delete_timestamp || '-' ||
old.object_count || '-' || old.bytes_used);
END;
CREATE TRIGGER container_insert AFTER INSERT ON container
BEGIN
UPDATE account_stat
SET container_count = container_count + (1 - new.deleted),
object_count = object_count + new.object_count,
bytes_used = bytes_used + new.bytes_used,
hash = chexor(hash, new.name,
new.put_timestamp || '-' ||
new.delete_timestamp || '-' ||
new.object_count || '-' || new.bytes_used);
END;
CREATE TRIGGER container_update BEFORE UPDATE ON container
BEGIN
SELECT RAISE(FAIL, 'UPDATE not allowed; DELETE and INSERT');
END;
其中ROWID字段表示自增的主键,name字段表示container的名称,put_timestamp和delete_timestamp分别表示container的put和delete的时间戳,object_count表示container内的object数,
bytes_used 表示已使用的空间,deleted表示container是否标记为删除。
账号test的account表中的数据项如下所示:
表incoming_sync记录到来的同步数据项,其schema如下:
CREATE TABLE incoming_sync (
remote_id TEXT UNIQUE,
sync_point INTEGER,
updated_at TEXT DEFAULT 0
);
CREATE TRIGGER incoming_sync_insert AFTER INSERT ON incoming_sync
BEGIN
UPDATE incoming_sync
SET updated_at = STRFTIME('%s', 'NOW')
WHERE ROWID = new.ROWID;
END;
CREATE TRIGGER incoming_sync_update AFTER UPDATE ON incoming_sync
BEGIN
UPDATE incoming_sync
SET updated_at = STRFTIME('%s', 'NOW')
WHERE ROWID = new.ROWID;
END;
remote_id字段表示远程节点的id,sync_point字段表示上一次更新所在的行位置,updated_at字段表示更新时间。
账号test的表incoming_sync中的数据项如下所示:

表outgoing_sync表示推送出的同步数据项,其schema如下
CREATE TABLE outgoing_sync (
remote_id TEXT UNIQUE,
sync_point INTEGER,
updated_at TEXT DEFAULT 0
);
CREATE TRIGGER outgoing_sync_insert AFTER INSERT ON outgoing_sync
BEGIN
UPDATE outgoing_sync
SET updated_at = STRFTIME('%s', 'NOW')
WHERE ROWID = new.ROWID;
END;
CREATE TRIGGER outgoing_sync_update AFTER UPDATE ON outgoing_sync
BEGIN
UPDATE outgoing_sync
SET updated_at = STRFTIME('%s', 'NOW')
WHERE ROWID = new.ROWID;
END;
remote_id字段表示远程节点的id,sync_point字段表示上一次更新所在的行位置,updated_at字段表示更新时间。
账号test的表remote_id中的数据项如下所示:

3.Container目录
Container目录结构和生成过程与Account类似,Containerdb中共有5张表,其中incoming_sync和outgoing_sync的schema与Account中的相同。其他3张表分别为container_stat、object、sqlite_sequence。
表container_stat与表account_stat相似,其区别是container_stat存放的是关于container信息:
CREATE TABLE container_stat (
account TEXT,
container TEXT,
created_at TEXT,
put_timestamp TEXT DEFAULT '0',
delete_timestamp TEXT DEFAULT '0',
object_count INTEGER,
bytes_used INTEGER,
reported_put_timestamp TEXT DEFAULT '0',
reported_delete_timestamp TEXT DEFAULT '0',
reported_object_count INTEGER DEFAULT 0,
reported_bytes_used INTEGER DEFAULT 0,
hash TEXT default '00000000000000000000000000000000',
id TEXT,
status TEXT DEFAULT '',
status_changed_at TEXT DEFAULT '0',
metadata TEXT DEFAULT '',
x_container_sync_point1 INTEGER DEFAULT -1,
x_container_sync_point2 INTEGER DEFAULT -1
);
其中account字段表示container所示的account,container字段表示container名称,created_at表示创建时间,put_timestamp表示put
request的时间戳,delete_timestamp表示delete request的时间戳,object_count表示object计数,bytes_used表示使用空间,hash表示db文件的哈希值,
reported_put_timestamp, reported_delete_timestamp, reported_object_count,
reported_bytes_used表示reported的状态信息,id表示统一标识符,status表示container状态,status_changed_at表示更改时间,metadata表示container的元数据,x_container_sync_point1表示同步点1,x_container_sync_point2表示同步点2.
以名称为test的container db为例,其中的表container_stat数据项如下:

表object的schema如下:
CREATE TABLE object (
ROWID INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
created_at TEXT,
size INTEGER,
content_type TEXT,
etag TEXT,
deleted INTEGER DEFAULT 0
);
CREATE INDEX ix_object_deleted_name ON object (deleted, name);
CREATE TRIGGER object_delete AFTER DELETE ON object
BEGIN
UPDATE container_stat
SET object_count = object_count - (1 - old.deleted),
bytes_used = bytes_used - old.size,
hash = chexor(hash, old.name, old.created_at);
END;
CREATE TRIGGER object_insert AFTER INSERT ON object
BEGIN
UPDATE container_stat
SET object_count = object_count + (1 - new.deleted),
bytes_used = bytes_used + new.size,
hash = chexor(hash, new.name, new.created_at);
END;
CREATE TRIGGER object_update BEFORE UPDATE ON object
BEGIN
SELECT RAISE(FAIL, 'UPDATE not allowed; DELETE and INSERT');
END;
test container db的表object数据项如下所示:

4. tmp目录
tmp目录作为account/container/object server向partition目录内写入数据前的临时目录。
例如,在client向服务端上传某一文件,object server调用DiskFile类的mkstemp方法在创建路径为path/device/tmp的目录。在数据上传完成之后,调用put()方法,将数据移动到相应路径。
5. async_pending目录
本地server在与remote server建立http连接或者发送数据时超时导致更新失败时,将把文件放入async_pending目录。这种情况经常发生在系统故障或者是高负荷的情况下。如果更新失败,本次更新被加入队列,然后由Updater继续处理这些失败的更新工作。例如,假设一个container
server处于负荷下,此时一个新的对象被加入到系统。当Proxy成功地响应Client的请求时,这个对象将变为直接可访问的。但是container服务器并没有更新对象列表,本次更新将进入队列等待延后的更新。所以,container列表不可能马上就包含这个新对象。随后Updater使用object_sweep扫描device上的async
pendings目录,遍历每一个prefix目录并执行升级。一旦完成升级,则移除pending目录下的文件(实际上,是通过调用renamer函数将文件移动到object相应的目录下)。
为了验证以上过程,通过执行一个并发上传1000个文件的脚本,观察sws50的async_pending目录下的所发生的变化。async_pending的路径为/srv/node/sdc/async_pending/,在执行脚本前,该目录下为空。脚本执行完毕后,async_pending目录下产生了一些prefix目录,cd到一个prefix为cb9的目录中,观察其中的数据:
root@sws50:/srv/node/sdc/async_pending/cb9# ll total 24 -rw------- 1 swift swift 324 2011-11-08 10:15 69a5ee25ea7a4a4b08ea47102930fcb9-1320718532.01864 -rw------- 1 swift swift 324 2011-11-08 10:15 69a5ee25ea7a4a4b08ea47102930fcb9-1320718537.04863 -rw------- 1 swift swift 324 2011-11-08 10:15 69a5ee25ea7a4a4b08ea47102930fcb9-1320718543.08122 -rw------- 1 swift swift 324 2011-11-08 10:15 69a5ee25ea7a4a4b08ea47102930fcb9-1320718550.13288 -rw------- 1 swift swift 324 2011-11-08 10:15 69a5ee25ea7a4a4b08ea47102930fcb9-1320718558.18801 -rw------- 1 swift swift 324 2011-11-08 10:16 69a5ee25ea7a4a4b08ea47102930fcb9-1320718567.25494
文件路径的组成如下图所示,其中数据名称是由hash_path后面紧跟’-‘,后面是以发送container
request的header中包含的时间戳所产生:

2分钟之后,查看该目录下的文件,仅剩下一个文件:
root@sws50:/srv/node/sdc/async_pending/cb9# ll
total 4
-rw——- 1 swift swift 356 2011-11-08 10:18 69a5ee25ea7a4a4b08ea47102930fcb9-1320718567.25494
最后,async_pending目录变为空。
account和container的db pending文件并不会独立地存在于async_pending目录下,它们的pending文件会与其db文件在一个目录下存放。例如:
某container的db文件为b8e7f40f8c2012d17aca4e0483d391d0.db,其pending文件为b8e7f40f8c2012d17aca4e0483d391d0.db.pending,一起存放在suffix目录1d0下。
再次执行测试脚本观察1d0目录下的变化,执行前pending文件的大小为0kb,执行过程中,pending的大小慢慢增加到12kb左右,接着又缓慢下降直到0kb。读取此过程某一时刻的pending文件。
其中内容如下所示:
‘:gAIoVQM3MzVxAVUQMTMyMTE4NjczMy4yNTQ0N3ECSgBwAQBVGGFwcGxpY2F0aW9uL29jdGV0LXN0
\ncmVhbXEDVSBkYmQzZjhmYjQ1ZmQyZjBkZGZmNTA1ODZkNWU0ZGY3ZnEESwB0Lg==\n:gAIoVQM3Mzh
xAVUQMTMyMTE4NjczMy41MjM4MXECTQDcVRhhcHBsaWNhdGlvbi9vY3RldC1zdHJl\nYW1xA1UgOGI3YzR
iZGVlYzNkZGU4ZDI5OWU1Yzk1ZmE1N2ExZWVxBEsAdC4=\n:gAIoVQM3MzlxAVUQMTMyMTE4NjczMy42M
zg0NnECTQCgVRhhcHBsaWNhdGlvbi9vY3RldC1zdHJl\nYW1xA1UgMmQ1ZDlhYjk0MzlkMTNiMmZhODhiZmF
mNTk3NTRkMjZxBEsAdC4=\n:g……………………………………AIoVQM3NDdxAVUQMTM
yMTE4NjczNC40MzIxNnECSgBoAQBVGGFwcGxpY2F0aW9uL29jdGV0LXN0\ncmVhbXEDVSBjYTgzNmZhY2Fh
MzY0MGQwNDc4YTU5OGQzZmUzYmRiNHEESwB0Lg==\n:gAIoVQM3NDlxAVUQMTMyMTE4NjczNC42MzA
1NXECTQCUVRhhcHBsaWNhdGlvbi9vY3RldC1zdHJl\nYW1xA1UgY2Y5NWU3MDIxNWEzOTFlNzcwZDBkODB
jZjlhN2Q5OTlxBEsAdC4=\n:gAIoVQM3NTBxAVUQMTMyMTE4NjczNC43NTA2MXECSgAoAQBVGGFwcGxpY2
F0aW9uL29jdGV0LXN0\ncmVhbXEDVSAyYzU4Zjc3ZGIwMGUxMTgxNjZmNjg2Zjc0YzlmZmNjZHEESwB0Lg==\n’
使用’:’对以上字符串进行分割成list,我们得到第一个非空元素
y[1]:’gAIoVQM3MzVxAVUQMTMyMTE4NjczMy4yNTQ0N3ECSgBwAQBVGG
FwcGxpY2F0aW9uL29jdGV0LXN0\ncmVhbXEDVSBkYmQzZjhmYjQ1ZmQyZjBk
ZGZmNTA1ODZkNWU0ZGY3ZnEESwB0Lg==\n’
使用pickle模块对其进行解码pickle.loads(y[1].decode(‘base64’)),获得一个dict类型的数据:
name, timestamp, size, content_type, etag,deleted=
(‘735’,
‘1321186733.25447’,
94208,
‘application/octet-stream’,
‘dbd3f8fb45fd2f0ddff50586d5e4df7f’,
0)
表示一个名称为’735’,大小为94208B,md5哈希值为dbd3f8fb45fd2f0ddff50586d5e4df7f,可访问的字节流文件。此过程由ContainerBroker类的_commit_puts方法完成,随后使用put_object方法把这些数据项放入container
db的object表中,.pending文件中的数据类型与object表中的字段定义一致。
从account与container的db和object两者的pending文件处理方式中发现其不同之处在于,db的pending文件在更新完其中的一项数据之后,删除pending文件中的相应的数据项,而object的数据在更新完成之后,移动pending文件到目标目录。
6. quarantined目录
Auditor进程会在本地服务器上每隔一段时间就扫面一次磁盘来检测account、container、object的完整性。一旦发现不完整的数据,该文件就会被隔离,该目录就称为quarantined目录。为了限制Auditor消耗过多的系统资源,其默
认扫描间隔是30秒,每秒最大的扫描文件数为20,最高速率为10Mb/s。
obj auditor使用AuditorWorker类的object_audit方法来检查文件的完整性,该方法封装了obj
server的DiskFile类,该类有一个_handle_close_quarantine方法,用来检测文件是否需要被隔离,如果发现损坏,则直接将文件移动到隔离目录下。随后replicator从其他replica那拷贝新的文件来替换,最后Server计算文件的hash值是否正确。整个处理流程如下所示:
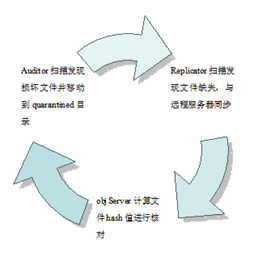
Figure7: quarantined object处理流程
为了验证auditor的有效性,做一个简单的测试,在路径为srv/4/node/sdb4/objects/210/82c/003499609ba80372d62aa39a9f9a482c/1321186693.02822.data的文件中随意写入了一串字符。约过了10秒之后,发现sdb4/目录下建立了一个quarantined目录,其中包含object目录,里面损坏了的文件,其路径为/srv/4/node/sdb4/quarantined/objects/003499609ba80372d62aa39a9f9a482c/1321186693.02822.data。此时,打开原目录下的文件,已恢复为修改前的状态。
account使用AccountAuditor类的account_audit方法,container使用ContainerAuditor类的container_audit方法对目录下的db文件进行检查。然而,我在测试时,对container目录下的某db文件进行了修改,大约经过了数分钟后,该db文件才被隔离。在阅读源代码时,发现account和container的auditor的扫面间隔与object差异较大。在类初始化时设置了一个interval的变量,默认为1800s,然后在run_forever中传入该参数到random函数来设置休眠时间,每次执行的间隔在180~1800s之间,也就是3到30分钟。设置较长间隔的原因,我认为主要是由于每次检查db文件前,需要锁住db文件,如果检查的频率过于频繁会影响存储节点的db正常的读写性能。
总结
存储结点上的各路径由不同的进程产生和维护,Accounts目录存放了关于account的信息,主要记录account下的container信息,Containes目录存放了关于
container的信息,主要记录了该container下的object信息,Objects目录则是存放了文件的数据和元数据,tmp目录用于数据写入以上目录前的临时目录,
async_pending存放未能及时更新而被加入更新队列的数据,quaraninued路径用于隔离发生损坏的数据。