初到美国这边的实验室,老板很爽快的给了个小集群,让我配置下Hadoop. 我很快就答应了.
不过问题也随之而已,其一是给的集群其实就是一远程登录账户,而且没有root权限;其二集群共10个节点,但是共享存储的。本人这方面知识少,找了一个星期资料,才知道是NFS的。
后来找到了一个帖子:《Hadoop – 将Hadoop建构在NFS以及NIF》,受到启发.
不过给的权限确实小,并无root权限,即能操作的目录仅在/home/my_user_name/目录下,幸好后来本人得知NFS下/tmp目录也是可以用的. 所以在这种艰苦的环境下,只能将用/tmp了.
其缺点就是:服务器的重启,/tmp会清空,从而Hadoop集群里的数据将丢失,好在本人只是做点research,不碍事!
下面讲下配置吧!
<b style="color:black;background-color:#ffff66">Hadoop</b> version: <b style="color:black;background-color:#ffff66">hadoop</b>-1.0.1</p><p>Java version: jdk1.6.0_12
0. 设置Java路径, 因为是NFS,而且本人权限只是user, 所以只能修改$HOME/.bash_profile
export JAVA_HOME=/usr/java/jdk1.6.0_12</p><p>export JRE_HOME=/usr/java/jdk1.6.0_12/jre</p><p>export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib</p><p>export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
然后使其生效:
source $HOME/.bash_profile
1. 编辑 conf/hadoop-env.sh, 添加JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.6.0_12/
export <b style="color:black;background-color:#ffff66">HADOOP</b>_LOG_DIR=/tmp/<b style="color:black;background-color:#ffff66">hadoop</b>_username_log_dir
2. 将 src/core/core-default.xml, src/hdfs/hdfs-default.xml, src/mapred/mapred-default.xml 复制到 conf下,并重命名为 core-site.xml, hdfs-site.xml, mapred-site.xml, 并编辑这三文件.
<!--core-site.xml--></p><p><property></p><p> <name>fs.default.name</name></p><p> <value>hdfs://head:9000</value></p><p> <description>The name of the default file system. A URI whose</p><p> scheme and authority determine the FileSystem implementation. The</p><p> uri's scheme determines the config property (fs.SCHEME.impl) naming</p><p> the FileSystem implementation class. The uri's authority is used to</p><p> determine the host, port, etc. for a filesystem.</description></p><p></property></p><p><property></p><p> <name><b style="color:black;background-color:#ffff66">hadoop</b>.tmp.dir</name></p><p> <value>/tmp/<b style="color:black;background-color:#ffff66">hadoop</b>-1.0.1_${user.name}</value></p><p> <description>A base for other temporary directories.</description></p><p></property>
<!--hdfs-site.xml--></p><p><property></p><p> <name>dfs.replication</name></p><p> <value>3</value></p><p> <description>Default block replication. </p><p> The actual number of replications can be specified when the file is created.</p><p> The default is used if replication is not specified in create time.</p><p> </description></p><p></property>
<!--mapred-site.xml--></p><p><property></p><p> <name>mapred.job.tracker</name></p><p> <value>head:9001</value></p><p> <description>The host and port that the MapReduce job tracker runs</p><p> at. If "local", then jobs are run in-process as a single map</p><p> and reduce task.</p><p> </description></p><p></property>
3. 这个是最重要的,我们需要再次编辑 conf/hadoop-env.sh,放在第一步编辑是完全可以的,这里放在最后一步,是为了强调!!就是修改HADOOP_LOG_DIR
export <b style="color:black;background-color:#ffff66">HADOOP</b>_LOG_DIR=/tmp/<b style="color:black;background-color:#ffff66">hadoop</b>-1.0.1_log_dir
4. 测试正常运行
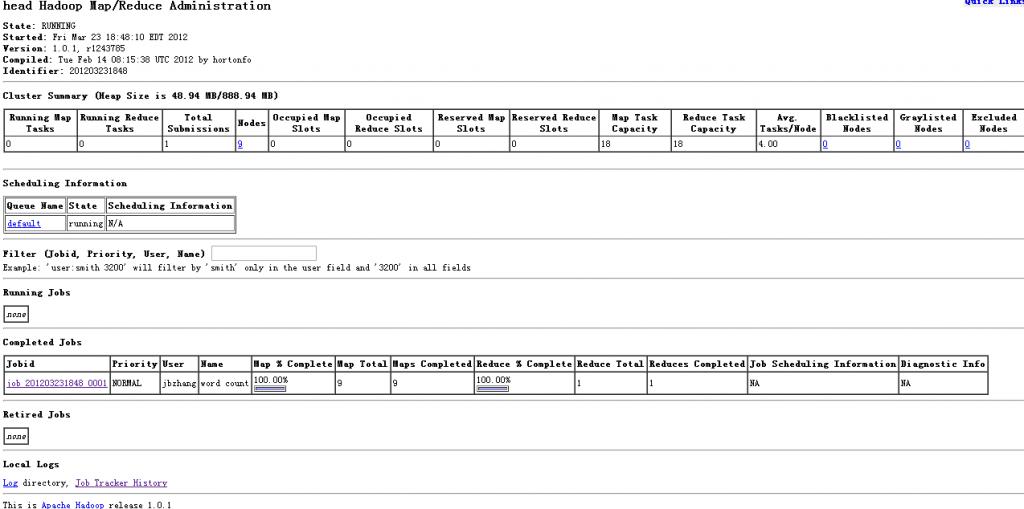
版权声明:本文为博