GAN的全称为Generative Adversarial Networks,意为对抗生成网络。原始的GAN是一种无监督学习方法,它巧妙地利用“对抗”的思想来学习生成式模型,一旦训练完成后可以生成全新的数据样本。DCGAN将GAN的概念扩展到卷积神经网络中,可以生成质量较高的图片样本。GAN和DCGAN在各个领域都有广泛的应用,这篇文章首先会介绍他们的原理,再介绍如何在TensorFlow中使用DCGAN生成图像,关于GAN和DCGAN的更多项目会在接下来的章节中进行介绍。
GAN的原理
GAN的原理其实非常简单。可以把GAN看成数据生成工具,这里以生成图片数据为例进行讲解,实际GAN可以应用到任何类型的数据。
假设有两个网络,生成网络G(Generator)和判别网络D(Discriminator)
他们的功能分别是:
- G负责生成图片,它接收一个随机的噪声z
,通过该噪声生成图片,将生成的图片记为G(z)
- 。
- D负责判别一张图片是不是“真实的”。它的输入时x
,x代表一张图片,输出D(x)表示x
- 为真实图片的概率,如果为,代表真实图片的概率为%,而输出为,代表不可能是真实的图片。
在训练过程中,生成网络G的目标是尽量生成真实的图片去欺骗判别网络D,而D的目标是尽量把生成的图片和真实的图片区分开来。这样,G和D构成了一个动态的“博弈”,这就是GAN的基本思想。
最后博弈的结果是什么?在理想的状态下,G可以生成足以“以假乱真”的图片G(z)
。对于D来说,他难以判定G生成的图片究竟是不是真实的,因此D(G(z))=0.5
。此时得到了一个生成式的模型G,他可以用来生成图片。
下面就用数学化的语言来描述这个过程。假设用于训练的真实图片数据是x
,图片数据的分布为Pdata(x),之前说G能够“生成图片”,实际G可以学习到真实的数据分布Pdata(x)。噪声z的分布设为pz(z),pz(z)是已知的,而Pdata(x)是未知的。在理想情况下,G(z)的分布应该尽可能接近Pdata(x),G将已知分布的z变量映射到了未知分布x
变量上。
根据交叉熵损失,可以构造下面的损失函数
V(D,G)=Ex∼Pdata(x)[lnD(x)]+Ez∼Pz(z)[ln(1−D(G(z)))]
损失函数中的Ex∼Pdata(x)是指在训练数据x中取得真实样本,而Ez∼Pz(z)
是指从已知的噪声分布中提取的样本。对于这个损失函数,需要认识下面几点:
- 整个式子由两项构成。x
表示真实图片,z表示输入G网络的噪声,而G(z)
- 表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))
- 是为了D判断G生成的图片是否真实的概率。
- G的目的:G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))
尽可能得大,这是V(D,G)
- 会变小。
- D的目的:D的能力越强,D(x)
应该越大,D(G(x))应该越小。因此D的目的和G不同,D希望V(D,G)
- 越大越好。
在实际训练中,使用梯度下降法,对D和G交替做优化即可,详细的步骤为:
- 从已知的噪声分布Pz(z)
中选出一些样本z(1),z(2),...,z(m)
- 。
- 从训练数据中选出同样个数的真实图片x(1),x(2),...,x(m)
- 。
- 设判别器D的参数为θd
,求出损失关于参数的梯度▽1m∑mi=1[lnD(xi)+ln(1−D(G(zi)))],对θd
- 更新时加上该梯度。
- 设生成器G的参数为θg
,求出损失关于参数的梯度▽1m∑mi=1[ln(1−D(G(zi)))],对θg
- 更新时减去该梯度。
在上面的步骤中,每对D的参数更新一次,便接着更新一次G的参数。有时还可以对D的参数更新k次后再更新一次G的参数,这些要根据训练的实际情况进行调整。另外,要注意的是,由于D是希望损失越大越好,G是希望损失损失越小越好,所以他们是一个加上梯度,一个是减去梯度。
当训练完成后,可以从Pzz
随机取出一个噪声,经过G运算后可以生成符合Pdata(x)
的新样本。
2 DCGAN的原理
DCGAN的全称是Deep Convolutional Generative Adversarial Networks ,
意即深度卷积对抗生成网络,它是由Alec Radford在论文Unsupervised
Representation Learning with Deep Convolutional Generative Adversarial
Networks中提出的。从名字上来看,它是在GAN的基础上增加深度卷积网
络结构,专门生成图像样本。下面一起来学习DCGAN的原理。
上一节详细介绍了D 、G 的输入输出租损失的走义,但关于D 、G 本身的结构并没高做过多的介绍。事实上, GAN 并没再对D 、G 的具体结构做出任何限制。DCGAN中的D 、G 的含义以及损失都和原始GAN中完全一致,但是它在D和G中采用了较为特殊的结构,以便对图片进行有效建模。
对于判别器D,它的输入是一张图像,输出是这张图像为真实图像的概率。在DCGAN中,判别器D的结构是一个卷积神经网络,输入的图像经过若干层卷积后得到一个卷积特征,将得到的特征送入Logistic函数,输出可以看作是概率。
对于生成器G ,它的网络结构如图8-1所示。
G的输入时一个100维的向量z。它是之前所说的噪声向量。G网络的第一层实际是一个全连接层,将100维的向量变成一个4x4x1024维的向量,从第二层开始,使用转置卷积做上采样,逐渐减少通道数,最后得到的输出为64x64x3,即输出一个三通道的宽和高都为64的图像。
此外,G、D还有一些其他的实现细节:
- 不采用任何池化层( Pooling Layer ),在判别器D 中,用带有步长( Stride)的卷积来代替池化层。
- 在G 、D 中均使用Batch Normalization帮助模型收敛。
- 在G中,激活函数除了最后一层都使用ReLU 函数,而最后一层使用tanh函数。使用tanh函数的原因在于最后一层要输出图像,而图像的像素值是有一个取值范围的,如0~255 。ReLU函数的输出可能会很大,而tanh函数的输出是在-1~1之间的,只要将tanh函数的输出加1再乘以127.5可以得到0~255 的像素值。
- 在D 中,激活函数都使用Leaky ReLU作为激活函数。
以上是DCGAN中D和G的结构,损失的定义以及训练的方法和第1节中描述的完全一致。Alec Radford使用DCGAN在LSUN数据集上进行无监督学习, LSUN是一个场景理解图像数据集,主要包含了卧室、固房、客厅、教室等场景图像。在LSUN的卧室数据集上,DCGAN生成的图像如图8-2所示。

除了使用G生成图像之外,还可以将G的输入信号z
看作生成图像的一种表示。假设图片A对应的输入为zA,图片B对应的输入为zB,可以在zA和zB
之间做插值,并使用G生成每一个插值对应的图片,对应的结果如图8-3所示。每一行的最左边可以看做图片A,而每一行的最右边可以看做是图片B,DCGAN可以让生成的图像以比较自然的方式从A过渡到B,并保证每一张过度图片都是卧室的图片。如图8-3所示的第六航中,一键没有窗户的卧室逐渐变化成了一间有窗户的卧室,在第四行中,一间有点事的卧室逐渐变化成了一间没有电视的卧室,原来电视的位置被窗帘取代,所有这些图片都是机器自动生成的。

实验证明,不仅可以对输入信号z进行过渡插值,还可以对它进行复杂运算。如图8-4所示,用代表“露出笑容的女性”的z
,减去“女性”,再加上“男性”,最后得到了“露出笑容的男性”。

3 在TensorFlow中用DCGAN生成图像
本节会以GitHub上的一个DCGAN项目介绍TensorFlow中的DCGAN实现。利用该代码主要去完成两件事,一是生成MNIST手写数字,二是在自己的数据集上训练。还会穿插讲解该项目的数据读入方法、数据可视化方法。
3.1 生成MNIST图像
先做一个简单的小实验:生成MNIST手写数字。
运行如下代码会下载MNIST数据集到data/mnist文件夹中。
<code class="hljs avrasm has-numbering">python download<span class="hljs-preprocessor">.py</span> mnist</code>
- 1
download.py 依赖一个名为tqdm的库,如果运行报错,可以先使用pip
install tqdm安装该库。
注意:当下载数据集时,如果出现网络问题导致下载中断, 在再次下载时必须先删除data/mnist 文件夹,否则download.py 会自动跳过下载。
下载完成后,使用下面的命令即可开始训练:
<code class="hljs brainfuck has-numbering"><span class="hljs-comment">python</span> <span class="hljs-comment">main</span><span class="hljs-string">.</span><span class="hljs-comment">py</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">dataset</span> <span class="hljs-comment">mnist</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_height=28</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">output_height=28</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">train</span></code>
- 1
参数的含义会在下面的小节中进行详细的介绍,先来关注运行该命令后屏幕显示的信息:
<code class="hljs css has-numbering"><span class="hljs-tag">Epoch</span>: <span class="hljs-attr_selector">[ 3]</span> <span class="hljs-attr_selector">[ 5/ 15]</span> <span class="hljs-tag">time</span>: 152<span class="hljs-class">.4979</span>, <span class="hljs-tag">d_loss</span>: 1<span class="hljs-class">.39733350</span>, <span class="hljs-tag">g_loss</span>: 0<span class="hljs-class">.68659568</span> <span class="hljs-tag">Epoch</span>: <span class="hljs-attr_selector">[ 3]</span> <span class="hljs-attr_selector">[ 6/ 15]</span> <span class="hljs-tag">time</span>: 155<span class="hljs-class">.5141</span>, <span class="hljs-tag">d_loss</span>: 1<span class="hljs-class">.39340806</span>, <span class="hljs-tag">g_loss</span>: 0<span class="hljs-class">.68581676</span> <span class="hljs-tag">Epoch</span>: <span class="hljs-attr_selector">[ 3]</span> <span class="hljs-attr_selector">[ 7/ 15]</span> <span class="hljs-tag">time</span>: 158<span class="hljs-class">.4942</span>, <span class="hljs-tag">d_loss</span>: 1<span class="hljs-class">.39538455</span>, <span class="hljs-tag">g_loss</span>: 0<span class="hljs-class">.68858492</span> <span class="hljs-tag">Epoch</span>: <span class="hljs-attr_selector">[ 3]</span> <span class="hljs-attr_selector">[ 8/ 15]</span> <span class="hljs-tag">time</span>: 161<span class="hljs-class">.3817</span>, <span class="hljs-tag">d_loss</span>: 1<span class="hljs-class">.39494920</span>, <span class="hljs-tag">g_loss</span>: 0<span class="hljs-class">.68842071</span> <span class="hljs-tag">Epoch</span>: <span class="hljs-attr_selector">[ 3]</span> <span class="hljs-attr_selector">[ 9/ 15]</span> <span class="hljs-tag">time</span>: 164<span class="hljs-class">.2292</span>, <span class="hljs-tag">d_loss</span>: 1<span class="hljs-class">.40010333</span>, <span class="hljs-tag">g_loss</span>: 0<span class="hljs-class">.67908889</span> <span class="hljs-tag">Epoch</span>: <span class="hljs-attr_selector">[ 3]</span> <span class="hljs-attr_selector">[ 10/ 15]</span> <span class="hljs-tag">time</span>: 167<span class="hljs-class">.2779</span>, <span class="hljs-tag">d_loss</span>: 1<span class="hljs-class">.40040839</span>, <span class="hljs-tag">g_loss</span>: 0<span class="hljs-class">.68134904</span></code>
- 1
- 2
- 3
- 4
- 5
- 6
Epoch[3][10/15]表示当前为第3个epoch,每个epoch内有15步,当前为第0步。默认会在MNIST数据集运行25个epoch。每个一段时间,程序会把生成的模型保存在checkpoint/mnist_64_28_28、文件夹中。此外,每隔100步,程序都会使用当前的G生成图像样本,并将图像保存在samples文件夹中。这些自动生成的图像以train开头,如train_20_0299.png表示是第20个epoch第299步生成的图像。根据这些图像,可以得知当前生成G的性能,从而决定是否可以停止训练。
运行完25个epoch时,生成的效果如图8-5所示。
3.2 使用自己的数据集训练
本节介绍如何使用自己的图片数据集进行训练。首先需要准备好图片数据将它们裁剪到统一大小。在数据目录chapter_8_data中已经准备好了一个动漫人物头像数据集faces.zip 。在源代码的data目录中新建一个anime目录(如果没有data目录可以自行新建) ,并将faces.zip中所高的图像文件解压到anime目录中。最后形成的项目结构为:

在项目根目录中运行下面的命令即可开始训练:
<code class="hljs brainfuck has-numbering"><span class="hljs-comment">python</span> <span class="hljs-comment">main</span><span class="hljs-string">.</span><span class="hljs-comment">py</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_height</span> <span class="hljs-comment">96</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_width</span> <span class="hljs-comment">96</span> <span class="hljs-comment">\</span>
<span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">output_height</span> <span class="hljs-comment">48</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">output_width</span> <span class="hljs-comment">48</span> <span class="hljs-comment">\</span>
<span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">dataset</span> <span class="hljs-comment">anime</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">crop</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">train</span> <span class="hljs-comment">\</span>
<span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">epoch</span> <span class="hljs-comment">300</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_fname_pattern</span> <span class="hljs-comment">"</span><span class="hljs-string">.</span><span class="hljs-comment">jpg"</span></code>
- 1
- 2
- 3
- 4
这里将参数设置为一共会训练300个epoch,实际可能并不需要那么多,读者同样可以观察samples文件夹下生成的样本图像来决定应该训练多少个
epoch 。
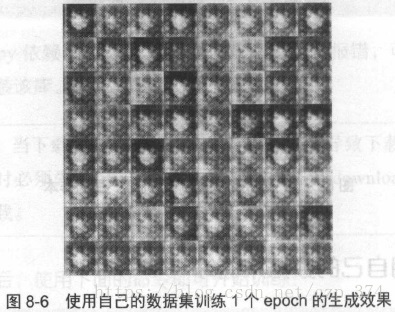
在训练1个epoch后,产生的样本图像如图8-6所示,此时只有模糊的边框(产生的图片在samples文件夹中)。
在训练5个epoch后,产生的样本如图8-7所示。

在训练50个epoch 后,产生的样本如图8-8所示,此时模型已经基本收敛了。

使用已经训练好的模型进行测试的对应命令为:
<code class="hljs brainfuck has-numbering"><span class="hljs-comment">python</span> <span class="hljs-comment">main</span><span class="hljs-string">.</span><span class="hljs-comment">py</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_height</span> <span class="hljs-comment">96</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_width</span> <span class="hljs-comment">96</span> <span class="hljs-comment">\</span>
<span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">output_height</span> <span class="hljs-comment">48</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">output_width</span> <span class="hljs-comment">48</span> <span class="hljs-comment">\</span>
<span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">dataset</span> <span class="hljs-comment">anime</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">crop</span></code>
- 1
- 2
- 3
3.3 程序结构分析:如何将图像读入模型
如果对第3.1、3.2节中的命令仍有所疑惑,本节会结合程序源码,对这些输入参数进行详细的分析。项目所有的功能入口为文件main.py,因此,先来看下main.py的大体结构。在这个文件中,首先定义了一些参数,然后将参数统一保存到变量FLAGS中,接着根据这些参数调用DCGAN(),新建一个模型,并保存到变量dcgan中。接下来的代码为:
<code class="hljs vbnet has-numbering"><span class="hljs-preprocessor"># 如果参数中指定为train,那么调用train方法进行训练</span>
<span class="hljs-keyword">if</span> FLAGS.train:
dcgan.train(FLAGS)
<span class="hljs-keyword">else</span>:
<span class="hljs-preprocessor"># 如果不需训练,直接去载入已经训练好的模型</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> dcgan.load(FLAGS.checkpoint_dir)[<span class="hljs-number">0</span>]:
raise Exception(<span class="hljs-string">"[!] Train a model first, then run test mode"</span>)
<span class="hljs-preprocessor"># Below is codes for visualization</span>
<span class="hljs-preprocessor"># 无论是进行训练还是直接执行,都会调用visualize方法进行可视化</span>
<span class="hljs-keyword">OPTION</span> = <span class="hljs-number">2</span>
visualize(sess, dcgan, FLAGS, <span class="hljs-keyword">OPTION</span>)</code>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
根据这段代码,在输入命令时,如果指定了–train,会进行训练,如果不指定–train,会载入己保存的模型,无论是进行训练还是不进行训练,都会调用visualize方法进行可视化。
以上是该项目的整体逻辑。下面介绍输入的命令行和输入图像有关的参数处理。–input_height、–input_width、–output_height、–output_width 、–dataset、–crop、–input_fname_pattern 这些参数。
首先–dataset、–input_fname_pattern 两个参数。在model.py中,找到下列代码:
<code class="hljs php has-numbering"><span class="hljs-comment"># mnist单独处理</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">self</span>.dataset_name == <span class="hljs-string">'mnist'</span>:
<span class="hljs-keyword">self</span>.data_X, <span class="hljs-keyword">self</span>.data_y = <span class="hljs-keyword">self</span>.load_mnist()
<span class="hljs-keyword">self</span>.c_dim = <span class="hljs-keyword">self</span>.data_X[<span class="hljs-number">0</span>].shape[-<span class="hljs-number">1</span>]
<span class="hljs-keyword">else</span>:
<span class="hljs-comment"># 在训练时,使用self.data中的数据</span>
<span class="hljs-comment"># 是data、dataset_name、self.input_fname_pattern</span>
<span class="hljs-keyword">self</span>.data = glob(os.path.join(<span class="hljs-string">"E:\datasets"</span>, <span class="hljs-keyword">self</span>.dataset_name, <span class="hljs-keyword">self</span>.input_fname_pattern))
<span class="hljs-comment"># 检查图片的通道数。一般是3通道彩色图</span>
imreadImg = imread(<span class="hljs-keyword">self</span>.data[<span class="hljs-number">0</span>]);
<span class="hljs-keyword">if</span> len(imreadImg.shape) >= <span class="hljs-number">3</span>: <span class="hljs-comment">#check if image is a non-grayscale image by checking channel number</span>
<span class="hljs-keyword">self</span>.c_dim = imread(<span class="hljs-keyword">self</span>.data[<span class="hljs-number">0</span>]).shape[-<span class="hljs-number">1</span>]
<span class="hljs-keyword">else</span>:
<span class="hljs-keyword">self</span>.c_dim = <span class="hljs-number">1</span></code>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
对于MNIST数据,程序是使用一个load_mnist()函数单独处理的。而对
于自己的数据集3 程序会在data 文件夹下根据dataset和input_fname pattern两个变量找图像文件。这里的self.dataset_name是输入参数dataset,
self.input_fname_pattern是输入参数input_fname pattern 。如输入dataset 为anime 、input_fname_pattern 为.jpg ,程序会自动寻找路径为data/anime/ .jpg的所有图片,即data/anime目录下的所有jpg图像。
读入所高图片的文件名后,又会做哪些操作呢?这涉及–input_height 、–input_width 、–crop 、–output_height 、–output_width五个参数。首先要说明的一点是,如果输入时不指定–input_width,那么它的值会和–input_height的值相同;同样,如果不指定–output_width,那么它的值会和–output_height相同。即main.py中的:
<code class="hljs oxygene has-numbering"><span class="hljs-keyword">if</span> <span class="hljs-keyword">FLAGS</span>.input_width <span class="hljs-keyword">is</span> None: <span class="hljs-keyword">FLAGS</span>.input_width = <span class="hljs-keyword">FLAGS</span>.input_height <span class="hljs-keyword">if</span> <span class="hljs-keyword">FLAGS</span>.output_width <span class="hljs-keyword">is</span> None: <span class="hljs-keyword">FLAGS</span>.output_width = <span class="hljs-keyword">FLAGS</span>.output_height</code>
- 1
- 2
- 3
- 4
读入的图片文件名首先经过以下操作(该部分代码在model.py 中):
<code class="hljs php has-numbering"><span class="hljs-comment"># mnist单独操作</span>
<span class="hljs-keyword">if</span> config.dataset == <span class="hljs-string">'mnist'</span>:
batch_images = <span class="hljs-keyword">self</span>.data_X[idx*config.batch_size:(idx+<span class="hljs-number">1</span>)*config.batch_size]
batch_labels = <span class="hljs-keyword">self</span>.data_y[idx*config.batch_size:(idx+<span class="hljs-number">1</span>)*config.batch_size]
<span class="hljs-keyword">else</span>:
<span class="hljs-comment"># self.data是所有图像文件名,batch_files是取出一个batch_size文件的文件名</span>
batch_files = <span class="hljs-keyword">self</span>.data[idx*config.batch_size:(idx+<span class="hljs-number">1</span>)*config.batch_size]
<span class="hljs-comment"># 调用get_image函数对每个图像进行处理</span>
batch = [
get_image(batch_file,
input_height=<span class="hljs-keyword">self</span>.input_height,
input_width=<span class="hljs-keyword">self</span>.input_width,
resize_height=<span class="hljs-keyword">self</span>.output_height,
resize_width=<span class="hljs-keyword">self</span>.output_width,
crop=<span class="hljs-keyword">self</span>.crop,
grayscale=<span class="hljs-keyword">self</span>.grayscale) <span class="hljs-keyword">for</span> batch_file in batch_files]
<span class="hljs-comment"># 区分灰度图和彩色图</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">self</span>.grayscale:
batch_images = np.<span class="hljs-keyword">array</span>(batch).astype(np.float32)[:, :, :, None]
<span class="hljs-keyword">else</span>:
batch_images = np.<span class="hljs-keyword">array</span>(batch).astype(np.float32)</code>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
self.data是之前说的存放所有图像文件路径的列表,每次都从该列表中取出batch_size大小的子集batch_files,对于batch_files中的每一个文件路径,调用get_image函数进行处理。
get_image函数在utils.py中,在此直接列出所有用到的函数:
<code class="hljs python has-numbering"><span class="hljs-comment"># get_image读入图像后直接使用transform函数</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">get_image</span><span class="hljs-params">(image_path, input_height, input_width,
resize_height=<span class="hljs-number">64</span>, resize_width=<span class="hljs-number">64</span>,
crop=True, grayscale=False)</span>:</span>
image = imread(image_path, grayscale)
<span class="hljs-keyword">return</span> transform(image, input_height, input_width,
resize_height, resize_width, crop)
<span class="hljs-comment"># transform函数</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">transform</span><span class="hljs-params">(image, input_height, input_width,
resize_height=<span class="hljs-number">64</span>, resize_width=<span class="hljs-number">64</span>, crop=True)</span>:</span>
<span class="hljs-keyword">if</span> crop:
<span class="hljs-comment"># 中心crop之后resize</span>
cropped_image = center_crop(
image, input_height, input_width,
resize_height, resize_width)
<span class="hljs-keyword">else</span>:
<span class="hljs-comment"># 直接resize</span>
cropped_image = scipy.misc.imresize(image, [resize_height, resize_width])
<span class="hljs-comment"># 标准化处理</span>
<span class="hljs-keyword">return</span> np.array(cropped_image)/<span class="hljs-number">127.5</span> - <span class="hljs-number">1.</span>
<span class="hljs-comment"># 中心crop,再进行缩放</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">center_crop</span><span class="hljs-params">(x, crop_h, crop_w,
resize_h=<span class="hljs-number">64</span>, resize_w=<span class="hljs-number">64</span>)</span>:</span>
<span class="hljs-keyword">if</span> crop_w <span class="hljs-keyword">is</span> <span class="hljs-keyword">None</span>:
crop_w = crop_h
h, w = x.shape[:<span class="hljs-number">2</span>]
j = int(round((h - crop_h)/<span class="hljs-number">2.</span>))
i = int(round((w - crop_w)/<span class="hljs-number">2.</span>))
<span class="hljs-keyword">return</span> scipy.misc.imresize(
x[j:j+crop_h, i:i+crop_w], [resize_h, resize_w])</code>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
get_image函数实际调用了transform 函数。transform 函数又使用了
center_crop函数。而center_crop函数的功能是:在图片中心截取高为crop_h像素,宽为crop_w像素的图片,再缩放为resize_h乘resize_w的大小。
再看transform函数,对输入图像的处理有两种方法。当指定–crop后,会调用center_crop函数。根据调用关系,这里的input_height和input_width是输入的–input_height和–input_ width参数,而resize_height和resize_width是输入的–output_height和–output_width参数。因此,实际是在图像中心截
取高为input_height乘以input_width的小块,并放缩到output_ height乘以
output_width的大小。此外,如果不指定参数–crop,不去截取图像,而是直接缩放到output_height乘output_width 。
这样的话,之前的执行指令非常好理解了,下面的命令:
<code class="hljs brainfuck has-numbering"><span class="hljs-comment">python</span> <span class="hljs-comment">main</span><span class="hljs-string">.</span><span class="hljs-comment">py</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_height</span> <span class="hljs-comment">96</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_width</span> <span class="hljs-comment">96</span> <span class="hljs-comment">\</span>
<span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">output_height</span> <span class="hljs-comment">48</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">output_width</span> <span class="hljs-comment">48</span> <span class="hljs-comment">\</span>
<span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">dataset</span> <span class="hljs-comment">anime</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">crop</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">train</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">epoch</span> <span class="hljs-comment">300</span> <span class="hljs-literal">-</span><span class="hljs-literal">-</span><span class="hljs-comment">input_fname_pattern</span> <span class="hljs-comment">"*</span><span class="hljs-string">.</span><span class="hljs-comment">jpg"</span></code>
- 1
- 2
- 3
对应的含义是:
- 找出data/anime/下所有jpg格式的图像。
- 将这些图像中心截取96×96的小块,并缩放到48 ×48像素。
- 因为有–train参数, 所以执行训练。
最后还有一个参数–epoch没解释,这个参数含义很好理解,代表执行的epoch数目。
3.4 程序结构分析:可视化方法
在训练好模型或者载入已有模型后,都会调用visualize方法进行可视化,即main.py中的如下代码:
<code class="hljs vbnet has-numbering"><span class="hljs-keyword">OPTION</span> = <span class="hljs-number">0</span> visualize(sess, dcgan, FLAGS, <span class="hljs-keyword">OPTION</span>)</code>
- 1
- 2
visualize函数在utils.py中。简单查看后可以发现该函数的输入参数option支持0、1、2、3、4一共5个值。在main. py 中直接更改OPTION的值可以使用不同的可视化方法。这里以option=0和option=1为例进行介绍。
option=0的可视化方法:
<code class="hljs perl has-numbering"><span class="hljs-comment"># image_fname_dim是batch_size开方之后向上取整的值</span>
image_frame_dim = <span class="hljs-keyword">int</span>(math.ceil(config.batch_size<span class="hljs-variable">**</span>.<span class="hljs-number">5</span>))
<span class="hljs-keyword">if</span> option == <span class="hljs-number">0</span>:
<span class="hljs-comment"># 生成batch_size个z噪声</span>
z_sample = np.random.uniform(-<span class="hljs-number">0</span>.<span class="hljs-number">5</span>, <span class="hljs-number">0</span>.<span class="hljs-number">5</span>, size=(config.batch_size, dcgan.z_dim))
<span class="hljs-comment"># 根据batch_size个z噪声生成batch_size张图片</span>
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
<span class="hljs-comment"># 将所有图片拼合成一张图片</span>
<span class="hljs-comment"># 这一张图片的格式为image_frame_dim乘以image_frame_dim</span>
save_images(samples, [image_frame_dim, image_frame_dim], <span class="hljs-string">'./samples/test_%s.png'</span> % strftime(<span class="hljs-string">"<span class="hljs-variable">%Y</span><span class="hljs-variable">%m</span><span class="hljs-variable">%d</span><span class="hljs-variable">%H</span><span class="hljs-variable">%M</span><span class="hljs-variable">%S</span>"</span>, <span class="hljs-keyword">gmtime</span>()))</code>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
程序首先根据batch_size的值计算出一个image_frame_dim 。这个值实际上是batch_size开方后再向上取整的结果。如默认的batch_size为64, 那么对应的image_frame_dim值是8 。
接着随机生成一些躁声z并保存为变量z_sample,它的形状为( batch size,z dim ),后者z_dim是单个噪声本身具有的维度,默认为100,这也和原始论文中的网络结构保持一致。在默认情况下,将生成一个形状为( 64, 100)的z_sample,z_sample中的每个值都在-0.5~0.5 之间。将它送入网络中,可以得到64张图像并放在samples中,最后调用save_images函数将64张图像组合为一张8*8的图像,如图8-9所示。

再看option=1的可视化方法:
<code class="hljs python has-numbering"><span class="hljs-keyword">elif</span> option == <span class="hljs-number">1</span>:
<span class="hljs-comment"># values是和batch_size等长的向量,从0~1递增</span>
values = np.arange(<span class="hljs-number">0</span>, <span class="hljs-number">1</span>, <span class="hljs-number">1.</span>/config.batch_size)
<span class="hljs-comment"># 会生成100张图片</span>
<span class="hljs-keyword">for</span> idx <span class="hljs-keyword">in</span> xrange(<span class="hljs-number">100</span>):
print(<span class="hljs-string">" [*] %d"</span> % idx)
<span class="hljs-comment"># 这里的z_sample大多数都是0</span>
z_sample = np.zeros([config.batch_size, dcgan.z_dim])
<span class="hljs-comment"># 实际上是把z_sample的第idx列变成values</span>
<span class="hljs-keyword">for</span> kdx, z <span class="hljs-keyword">in</span> enumerate(z_sample):
z[idx] = values[kdx]
<span class="hljs-keyword">if</span> config.dataset == <span class="hljs-string">"mnist"</span>:
<span class="hljs-comment"># 对mnist分开处理</span>
y = np.random.choice(<span class="hljs-number">10</span>, config.batch_size)
y_one_hot = np.zeros((config.batch_size, <span class="hljs-number">10</span>))
y_one_hot[np.arange(config.batch_size), y] = <span class="hljs-number">1</span>
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
<span class="hljs-keyword">else</span>:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], <span class="hljs-string">'./samples/test_arange_%s.png'</span> % (idx))</code>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
option=1的可视化方法会生成100张和option=0中差不多的图片。每个
z_sample中的数字大多数都是0,某中第idx( idx 从0~99)列变成一个事先
定义好的向量values。因此每个z_sample中各个图片对应的改变很小。图
8-10展示了使用option=1进行可视化生成的图片(变化比较细微) 。

剩下的几种可视化方法我们可以自行参阅源码进行分析。注意option=2 、
3、4 的几种方法都依赖一个名为moviepy的库。可以使用pip install moviep y安装,并保证import moviepy.editor as mpy不会出错。
4 总结
本章首先讲解了GAN和DCGAN的原理,接着介绍了一个非常有趣的项目:在TensorFlow中利用DCGAN生成图片。最后,以输入图像和可视化方法两部分为例,分析了DCGAN 项目的源码。希望通过这篇文章的介绍,掌握GAN的思想以及DCGAN的使用方法。
z
来源URL:https://blog.csdn.net/czp_374/article/details/81199055